| unix.ba | text • research • links • about |
A hole in the code
This is a basic description of an idea, so don't expect anything very elaborate. The discussion in this text is very theoretical, but I hope it will trigger some usable ideas along the way. Presented is a simple case in which two processes execute on a single CPU.
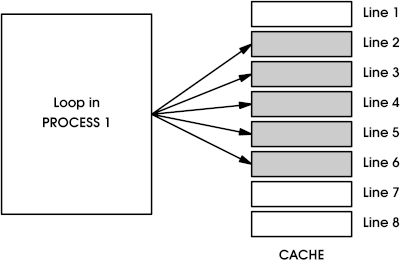
Figure 1 - Mapping of a loop in Process 1 into the instruction cache
Figure 1 shows a loop somewhere in the code of Process 1 and its mapping within the instruction cache. We assume here the simplest case of a one-way set associative (direct mapped) cache, although a cache in any modern CPU will usually have a bigger set size.
Let's suppose that Process 2 is also executing a loop which, unfortunately for us, maps to lines 4 and 5 of the instruction cache (Figure 2). This means that upon every context switch between Process 1 and Process 2 lines 4 and 5 of the instruction cache are invalid and must be re-read from memory. Notice, too, that we assume a cache which doesn't have to be fully flushed upon each context switch.
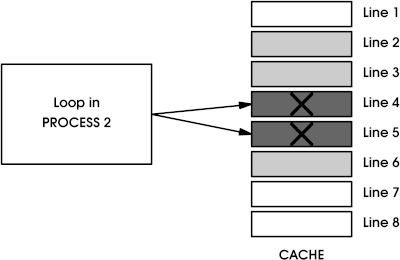
Figure 2 - A loop in Process 2 invalidating cache lines 4 and 5
To prevent invalidation of the part of instruction cache which is common to Process 1 and Process 2 (i.e. lines 4 and 5), we could split the loop of Process 1 into two parts as depicted by Figure 3. The first part of the loop fits into lines 2 and 3 of the cache and the second part is relocated so it aligns with cache lines 6, 7 and 8. The gap between the two parts is skipped with a simple unconditional jump, and is thus never executed. This way we should be able to intersperse both loops (of Process 1 and Process 2) inside the cache and preserve the contents of all cache lines (2 to 8) across multiple context switches.
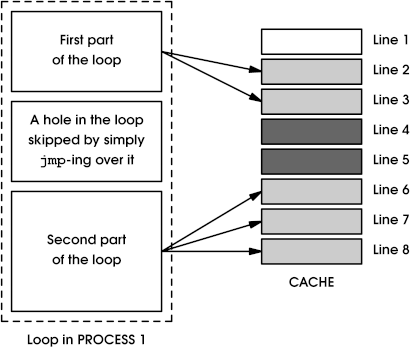
Figure 3 - Interspersed loops from Process 1 and Process 2
The presented concept could be a good starting point for a research of compile-time or runtime relocation of code and data on single- and multi-core processors to achieve an optimal distribution of cache lines among all processes.
• • •